
I am Yang Jin (金阳), a Ph.D. student at Wangxuan Institute of Computer Technology (WICT) in Peking University, advised by Prof. Yadong Mu. Before that, I obtained my B.S. degree in Computer Science and Engineering from Beihang University. I have been a research intern at ByteDance and Kuaishou Technology.
My research interests cover (1) Multi-modal Large Language Model and large-scale vision-language pre-training (2) AIGC including image, video, and personalized generation with both diffusion and autoregressive models (3) Video Understanding covers both recognition and localization tasks. I have published several papers and been reviewers at many conferences such as CVPR, ECCV, ICCV. If you are interested in my research, feel free to contact me through e-mail.
🔥 News
- 2025.01: One paper is accepted at ICLR 2025!
- 2024.09: One paper is accepted at NeurIPS 2024!
- 2024.07: One paper is accepted at ECCV 2024!
- 2024.05: One paper is accepted at ICML 2024 as an Oral presentation!
- 2024.01: One paper is accepted at ICLR 2024!
- 2023.07: One paper is accepted at ICCV 2023!
- 2023.03: One paper is accepted at CVPR 2023!
- 2022.09: One paper is accepted at NeurIPS 2022 as a spotlight presentation!
- 2022.03: One paper is accepted at CVPR 2022!
- 2021.04: One paper is accepted at TMM 2021!
📝 Publications
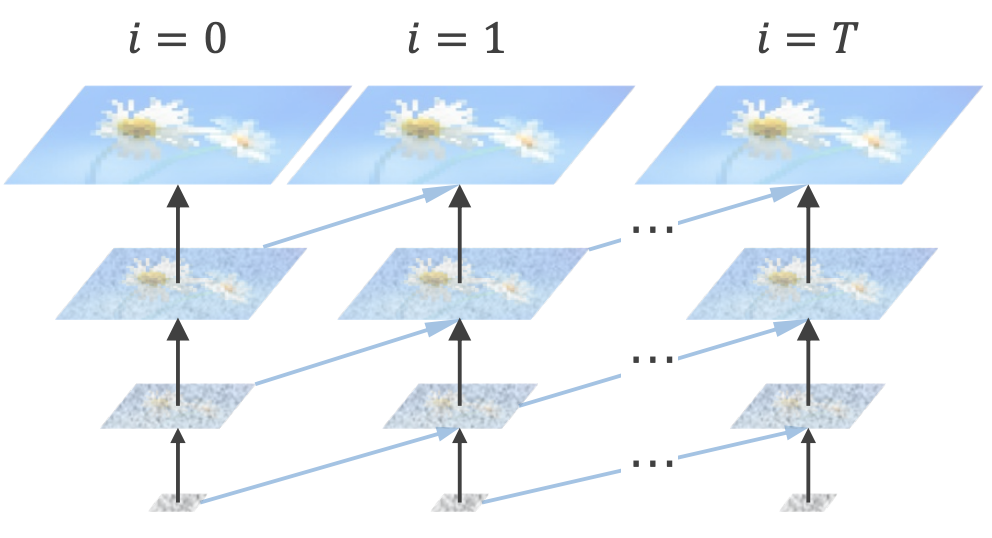
[ICLR 2025] Pyramidal Flow Matching for Efficient Video Generative Modeling
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, Zhouchen Lin
- We design a unified flow matching objective that jointly generates and decompresses visual content across pyramidal representations.
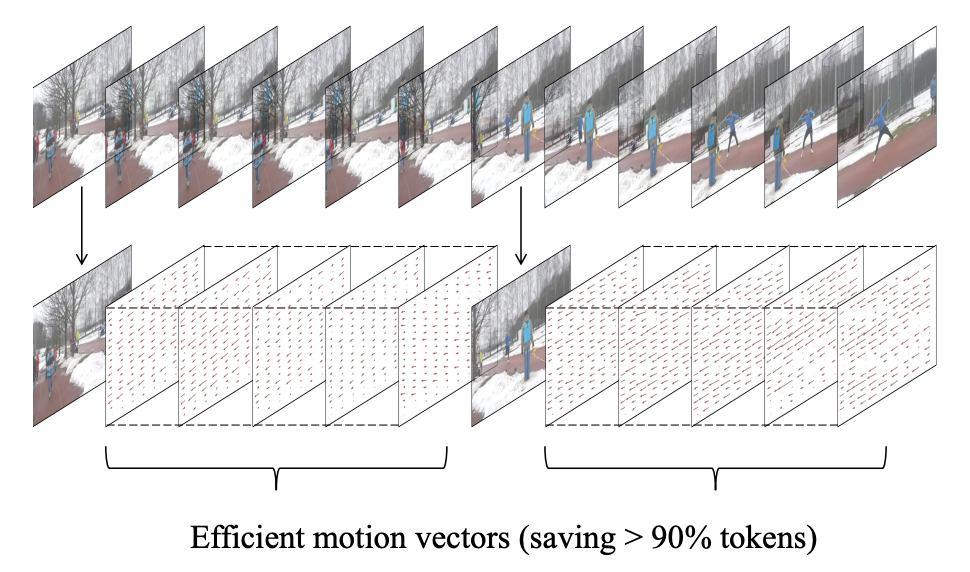
[ICML 2024 Oral] Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization
Yang Jin, Zhicheng Sun, Kun Xu, Kun Xu, Liwei Chen, Hao Jiang, Quzhe Huang, Chengru Song, Yuliang Liu, Di Zhang, Yang Song, Kun Gai, Yadong Mu
- We present a multimodal LLM capable of both comprehending and generating videos, based on an efficient decomposed video representation.
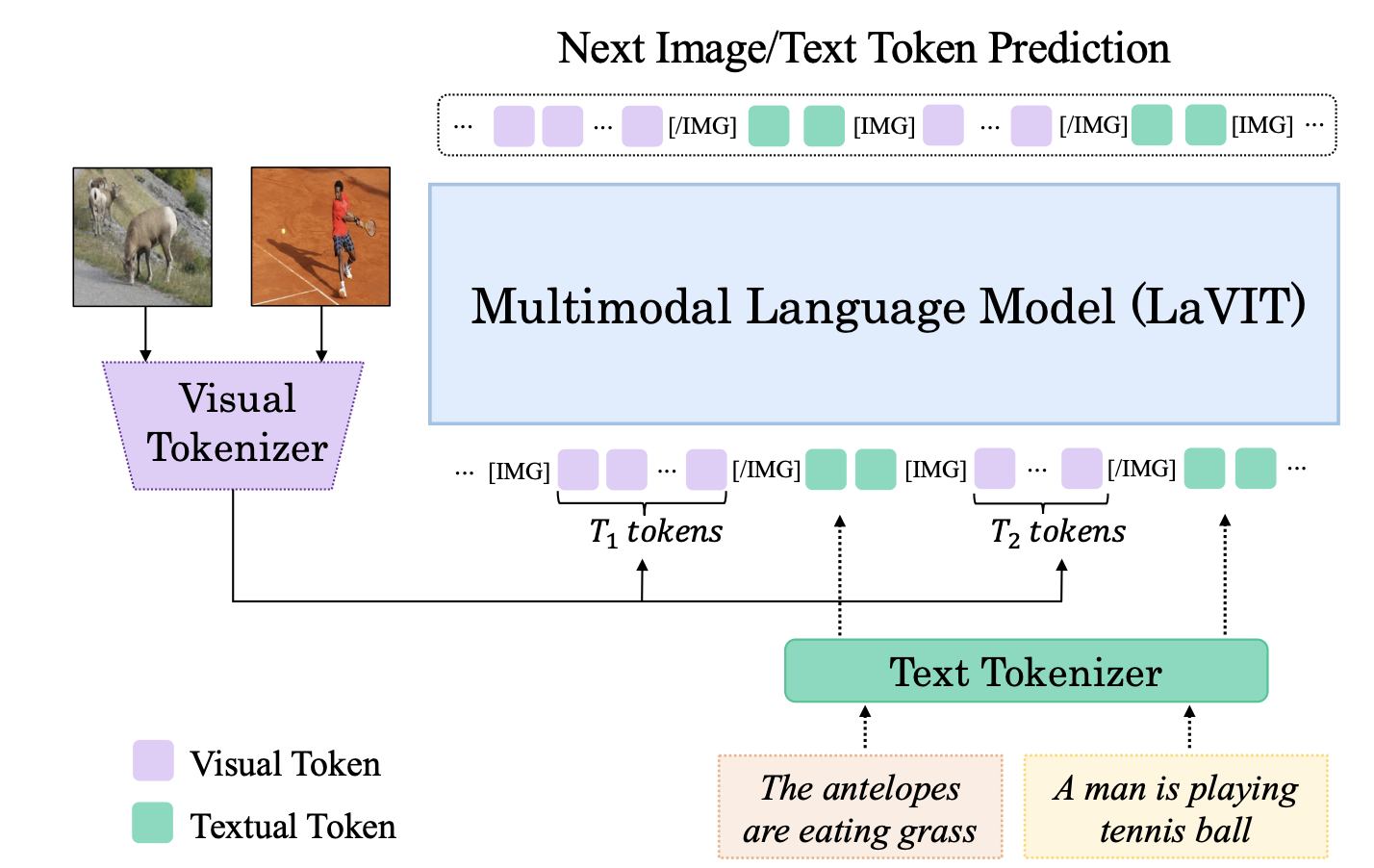
[ICLR 2024] Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization
Yang Jin, Kun Xu, Kun Xu, Liwei Chen, Chao Liao, Jianchao Tan, Quzhe Huang, Bin Chen, Chenyi Lei, An Liu, Chengru Song, Xiaoqiang Lei, Di Zhang, Wenwu Ou, Kun Gai, Yadong Mu
- We present an effective dynamic discrete visual tokenizer that represents an image as the foreign language in Large Language Models, which supports both multi-modal understanding and generation.
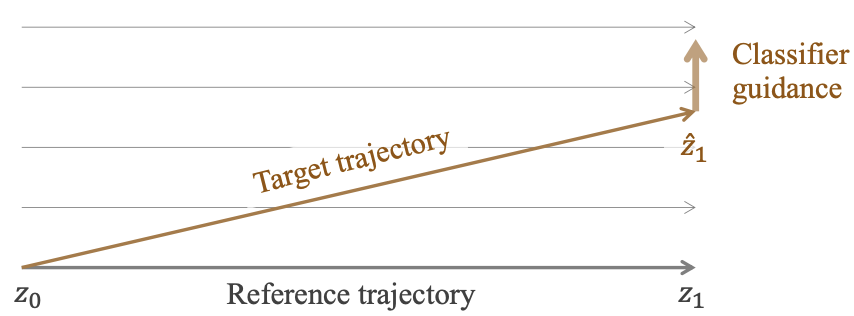
[NeurIPS 2024] RectifID: Personalizing Rectified Flow with Anchored Classifier Guidance
Zhicheng Sun, Zhenhao Yang, Yang Jin, Haozhe Chi, Kun Xu, Kun Xu, Liwei Chen, Hao Jiang, Di Zhang, Yang Song, Kun Gai, Yadong Mu
- We introduce a training-free approach to personalizing rectified flow, based on a fixed-point formulation of classifier guidance.
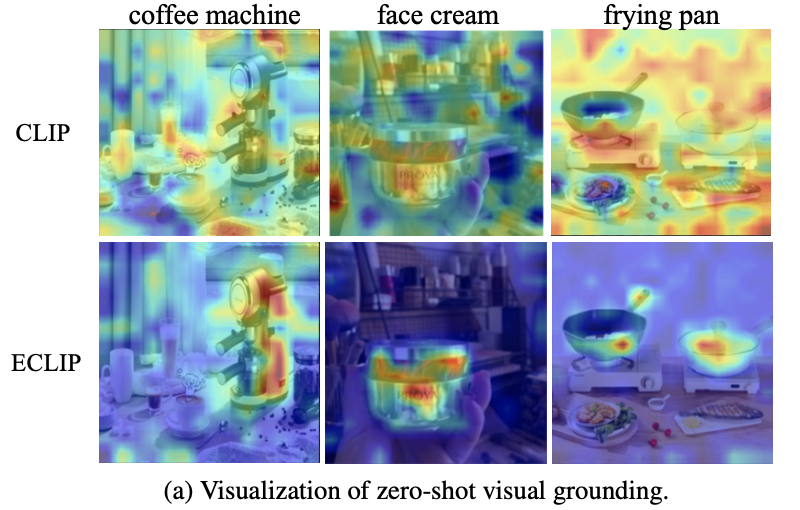
[CVPR 2023] Learning Instance-Level Representation for Large-Scale Multi-Modal Pretraining in E-commerce
Yang Jin, Yongzhi Li, Zehuan Yuan, Yadong Mu
- We propose a generic multi-modal foundation model in E-commerce that learns the instance-level representation of products and achieves superior performance on massive downstream E-commerce applications.
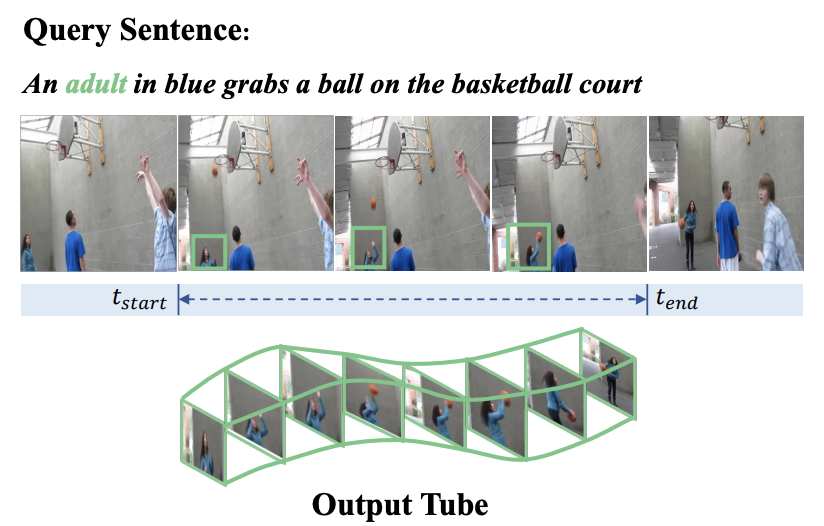
[NeurIPS 2022 Spotlight] Embracing Consistency: A One-Stage Approach for Spatio-Temporal Video Grounding
Yang Jin, Yongzhi Li, Zehuan Yuan, Yadong Mu
- We propose STCAT, a new one-stage spatio-temporal video grounding model that enjoys more consistent cross-modal feature alignment and tube prediction. It also achieved state-of-the-art performance on VidSTG and HC-STVG benchmarks.
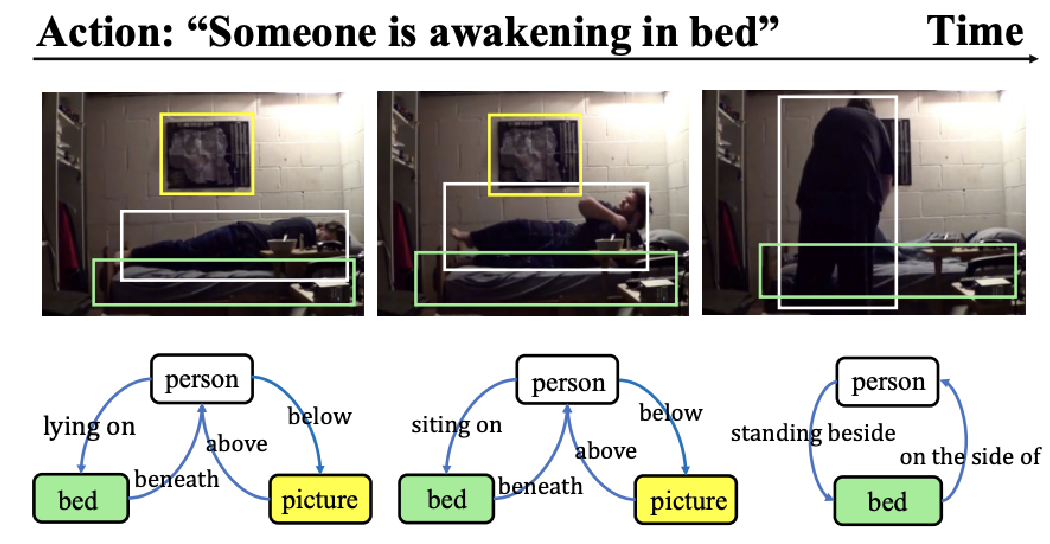
[CVPR 2022] Complex Video Action Reasoning via Learnable Markov Logic Network
Yang Jin, Linchao Zhu, Yadong Mu
- We devise an video action reasoning framework that performs Markov Logic Network (MLN) based probabilistic logical inference. The proposed framework enjoys remarkable interpretability through the learned logical rules.

[TMM 2021] Zero-Shot Video Event Detection with High-Order Semantic Concept Discovery and Matching
Yang Jin, Wenhao Jiang, Yi Yang, Yadong Mu
- We design an effective zero-shot video event retrieval framework based on the utilization of high-order concepts (such as subject-predicate-object triplets or adjective-object). The constructed high-order concept library and proposed query-expanding scheme significantly improved the perfromance.
-
Video Action Segmentation via Contextually Refined Temporal Keypoints, Borui Jiang, Yang Jin, Zhentao Tan, Yadong Mu, ICCV 2023
-
Beyond Short-Term Snippet: Video Relation Detection with Spatio-Temporal Global Context, Chenchen Liu, Yang Jin, Kehan Xu, Guoqiang Gong, Yadong Mu, CVPR 2020
🎖 Honors and Awards
- Peking University President’s Scholarship
- Wang Xuan Scholarship
- Peking University Study Excellence Award
- Peking University Excellent Research Award
📖 Educations
- 2020.09 - 2025.07 (expected), Ph.D. Student, Academy for Advanced Interdisciplinary Studies, Peking University.
- 2016.09 - 2020.07, Undergraduate Student, School of Computer Science and Engineering (SCSE), Beihang University.
💻 Internships
- 2023.07 - now, Content Understanding and Generation Group, Kuaishou Technology, China.
- 2022.04 - 2023.06, Content Understanding Group, ByteDance, China.
🏫 Professional Services
- Reviewer for CVPR 2023, CVPR 2024, ICCV 2023, ECCV 2024.